
Autonomous Adaptive Analytics: Safe Agents that Analyze, Execute, and Explain
TL;DR: Build an autonomous AI agent that detects issues, writes code, self-heals from errors, and delivers production-ready analysis, all inside secure, isolated sandboxes.
Section I: Why AI Analytics Still Falls Short
The Problem: It's 3 AM. Your ML pipeline fails on row 4,732 (NULL value). A data scientist wakes up, debugs for 90 minutes, adds .dropna(), and restarts. The analysis completes, but required manual intervention.
Current AI systems can't adapt autonomously. When analyses hit unexpected issues (distribution drift, missing data, failed assumptions), they stop and wait for humans. Static pipelines lack decision-making capabilities.
Our Solution: A closed-loop AI agent running in secure, isolated sandboxes that:
- Detects issues: Missing data, errors, invalid assumptions
- Decides & adapts: Retry with fixes, pivot methods, adjust parameters
- Executes autonomously: Writes code, self-heals, continues to completion
This is adaptive intelligence, not just automation.
How This Compares to Traditional Approaches
| Manual Analysis | Static ML Pipeline | Autonomous AI Analysis | |
|---|---|---|---|
| Adaptability | High but slow | Low, brittle to change | High and fast |
| When Errors Occur | Manual debugging | Pipeline stops, needs code fix | Self-heals, continues |
| Time to Results | Hours to days | Minutes (best case), hours (with issues) | 10-15 mins regardless |
| Best For | Novel research | Known data patterns | Exploratory analysis, iteration |
Demonstration: We'll walk through one complete analysis using Naive Bayes classification to classify 100 news pieces into 20 topic categories. The same autonomous system can run Random Forest or other ML methods by changing a single configuration variable - demonstrating true method-agnostic adaptability.
Watch the agent explore data, write code, handle errors, and deliver production-ready results without human intervention.
📓 Try It Yourself
We've published a Jupyter notebook that demonstrates this autonomous analysis system with configurable ML methods.
🔧 Choose Your Classification Method:
This simple one-line configuration lets you switch between classification approaches without any code changes—the autonomous agent adapts its implementation automatically. We'll focus on Naive Bayes in this walkthrough.
💡 Tip: For the easiest experience, run this notebook in Google Colab:
- Download the notebook from GitHub
- Go to colab.research.google.com
- Click "Upload" and select the downloaded notebook
This gives you a free cloud environment
Section II: Minimum Design Requirements for Our Solution
After experimenting with different approaches, we decided on these four principles that will make AI autonomous analysis safe, effective, and reliable for production:
1. Security & Tenant Isolation
Per-tenant, short-lived sandboxes with no shared state or persistent credentials. Everything cleans up automatically. This gives customers hard isolation without operational drag.
2. Closed-Loop Decision Engine
The agent owns the how: it chooses data exploration steps, analysis methods, and visualizations, not a prewritten script.
3. Autonomous Error Recovery
When runtime issues arise (OOM, package conflicts), the agent adapts, then continues from the last good checkpoint. Just like a human would do.
4. Observability & Governance
Every decision is logged with rationale; runs are bounded by policy (steps/time/cost); outputs are reproducible artifacts (charts, scripts, reports, decision log).
What You Need to Know Before We Begin
| Component | Purpose | Type | Key Features |
|---|---|---|---|
| 🏗️ Daytona | Ephemeral sandboxes | Product (requires registration) | • Per-tenant isolation • Fast spin-up & reproducibility |
| 🤖 Claude Code SDK | Autonomous coding agent | SDK/Library | • Read/Write/Edit/Bash/Glob/Grep tools • Closed-loop pattern (detect, decide, act, evaluate) • Structured logging & runnable code generation |
| 📤 Data Transfer | Secure file handling | Function | • Direct upload via sandbox.fs.upload_file()• No embedded credentials or persistent storage • API keys injected as environment variables |
| 📥 Result Extraction | Output management | Function | • Direct filesystem download • Categorized by type for clean handoff |
| 🔑 API Keys Required | Authentication | Registration required | • Anthropic API key for Claude Code • Daytona API key for sandbox access • Insert both in the Jupyter notebook placeholders |
Section III: Building the Analysis Flow - Step by Step
In this section, we will walk through the process, from start to finish: question to agent to answer, using the 20-Newsgroups data with Naive Bayes classification as the anchor example. The same flow applies to any classification method you configure.

Step 1/6: Prepare Dataset Locally
Download the 20 Newsgroups dataset and sample 1,000 posts to balance speed with statistical power. The dataset is exported to CSV format for sandbox compatibility.
Output: 20newsgroups_1000.csv (1,000 rows × 3 columns: text, target, category_name)
💡 Key Highlights
✓ Standard multi-class dataset (20 categories)
✓ Balanced sampling (1,000 posts)
✓ CSV format for universal compatibility
Step 2/6: Start Daytona Sandbox
Create an isolated, ephemeral sandbox environment with automatic cleanup.
💡 Key Highlights
✓ Session-based caching for warm reuse ✓ Complete tenant isolation ✓ Zero persistent state

Step 3/6: Upload Dataset to Sandbox
Transfer the prepared CSV file securely to the isolated sandbox environment.
For multiple files, concurrent uploads improve performance:
💡 Key Highlights
✓ Direct file transfer via
sandbox.fs.upload_file()✓ Concurrent uploads for multiple files ✓ No persistent credentials or storage
Step 4/6: Build Analysis Prompt & Execute Autonomously
This is the core autonomous execution step where we hand off control to the coding agent running inside the Daytona sandbox.
What Happens Here:
A. Create the Generation Script
We build a Python script (generate_analysis.py) that embeds the Claude Code SDK and the complete analysis prompt. Here's the actual script creation from the notebook:
This script packages:
- The analysis prompt with your business requirements (classify 100 posts, generate report, create visualizations)
- Claude Code SDK configured with 60-turn limit and tool permissions
- Tool allowlist: Read, Write, Edit, Bash, Glob, Grep for autonomous file and code operations
- Simple progress tracking showing message types as they're processed
🔧 Method-Agnostic Architecture
The script builder shown above works with any classification method. The notebook includes two prompt builders:
build_naive_bayes_prompt()- Naive Bayes implementation (used in this demo)build_random_forest_prompt()- Random Forest implementationBoth share identical analysis/reporting sections via
get_shared_analysis_instructions(), ensuring consistent outputs regardless of method. The autonomous agent receives the appropriate prompt based on yourCLASSIFICATION_METHODconfig—no manual intervention required.
B. Upload Script to Daytona Sandbox
The generated script is uploaded to /workspace/coding_agent/generate_analysis.py in the Daytona environment:
C. Execute Analysis with Simple Error Handling
We trigger the script remotely inside Daytona and handle results:
Key details:
- Runs inside the sandbox: The Python process executes in Daytona's isolated environment
- Environment injection:
ANTHROPIC_API_KEYpassed securely via environment variable - Working directory:
/workspace/coding_agent/where the dataset CSV already exists - Simple error handling: Clear user messages with retry instructions
- Timeout: 25 minutes to handle 60 tool-using turns with API calls
D. Autonomous Agent Execution Inside Daytona
Once started, Claude Code runs completely autonomously:
- Read tools: Explores
20newsgroups_1000.csvstructure and samples content - Write tools: Creates Python scripts for Naive Bayes training and prediction
- Bash tool: Executes classification code, generates visualizations, processes results
- Edit tools: Refines code based on errors or intermediate results
- Self-directed iteration: Agent decides its own implementation approach (no hardcoded steps)
 Example of Claude Code execution logs showing autonomous decision-making and tool usage
Example of Claude Code execution logs showing autonomous decision-making and tool usage
This is the Heart of the System
Step 4 represents the core autonomous execution, where control is fully handed off to the AI agent. The agent explores data, writes code, fixes errors, and generates complete analysis outputs without human intervention. Everything happens inside the secure Daytona sandbox with no access to external systems.
Now that the agent has completed its work, we move to the final phase: retrieving the generated artifacts and organizing them for human review.
Step 5/6: Download and Parse Results
Extract all generated files from the sandbox filesystem.
💡 Key Highlights
✓ Direct filesystem download from sandbox ✓ Automatic filtering (excludes temp files & uploaded data) ✓ Per-file error handling for graceful degradation ✓ Binary-safe content handling for images/charts
Step 6/6: Save Results Locally
Organize all outputs in a timestamped directory for reproducibility and audit trails.
💡 Key Highlights
✓ Timestamped directories for reproducibility ✓ Binary-safe file handling (images, CSVs, markdown) ✓ Clean handoff ready for downstream systems ✓ Complete audit trail preserved
Section IV: Actual Results - Naive Bayes Classification
The autonomous agent successfully completed the Naive Bayes analysis end-to-end. Here's what we learned:
🎯 Key Finding
The agent achieved 55% overall accuracy across 20 diverse newsgroup categories, with perfect (100%) classification on politically-focused topics and challenges on technical/religious categories requiring more sophisticated approaches.
⚡ Autonomous Recovery Highlight
Without human intervention, the agent:
- Detected and removed 15 entries with missing values (NaN in text field)
- Applied stratified sampling to ensure category representation in test set
- Installed missing
seabornlibrary when visualization failed- Continued from last checkpoint and delivered complete results
Performance Breakdown
Overall Metrics:
- Accuracy: 55.00% (55/100 correct predictions)
- Test Set: 100 posts sampled from 985 valid posts
- Training Set: 885 posts
- Categories: 20 distinct newsgroup topics
Category Performance Analysis
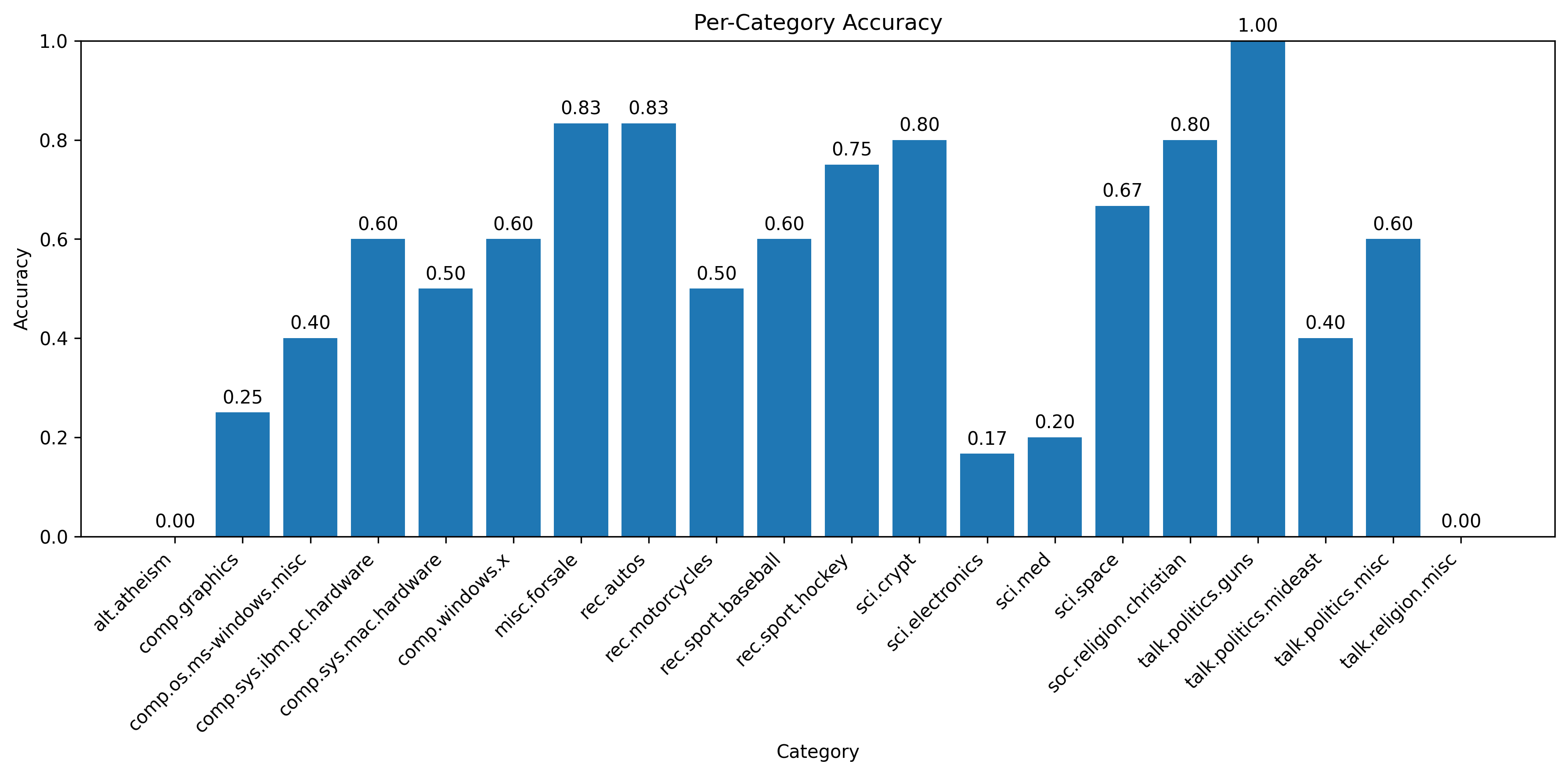
| Performance Tier | Categories | Example |
|---|---|---|
| Perfect (100%) | 1 category | talk.politics.guns (6/6) |
| Strong (80-90%) | 4 categories | misc.forsale (83%), rec.autos (83%), sci.crypt (80%) |
| Medium (50-79%) | 8 categories | rec.sport.hockey (75%), sci.space (67%) |
| Poor (<50%) | 7 categories | sci.electronics (17%), alt.atheism (0%) |
Key Insights from Analysis Report
What Worked Well:
- Distinctive vocabulary topics (politics.guns, forsale, autos, cryptography) achieved 80%+ accuracy
- Clear thematic separation enabled strong classification in well-defined domains
- TF-IDF with bigrams effectively captured topic-specific terminology patterns
What Struggled:
- Religious/political overlap:
alt.atheismandtalk.religion.misccompletely misclassified (0% accuracy) - Technical category confusion: Computer/science categories shared vocabulary, causing cross-classification
- Small test samples: Some categories had only 3-4 test instances, limiting statistical confidence
 Analysis.md file Snapshot
Analysis.md file Snapshot
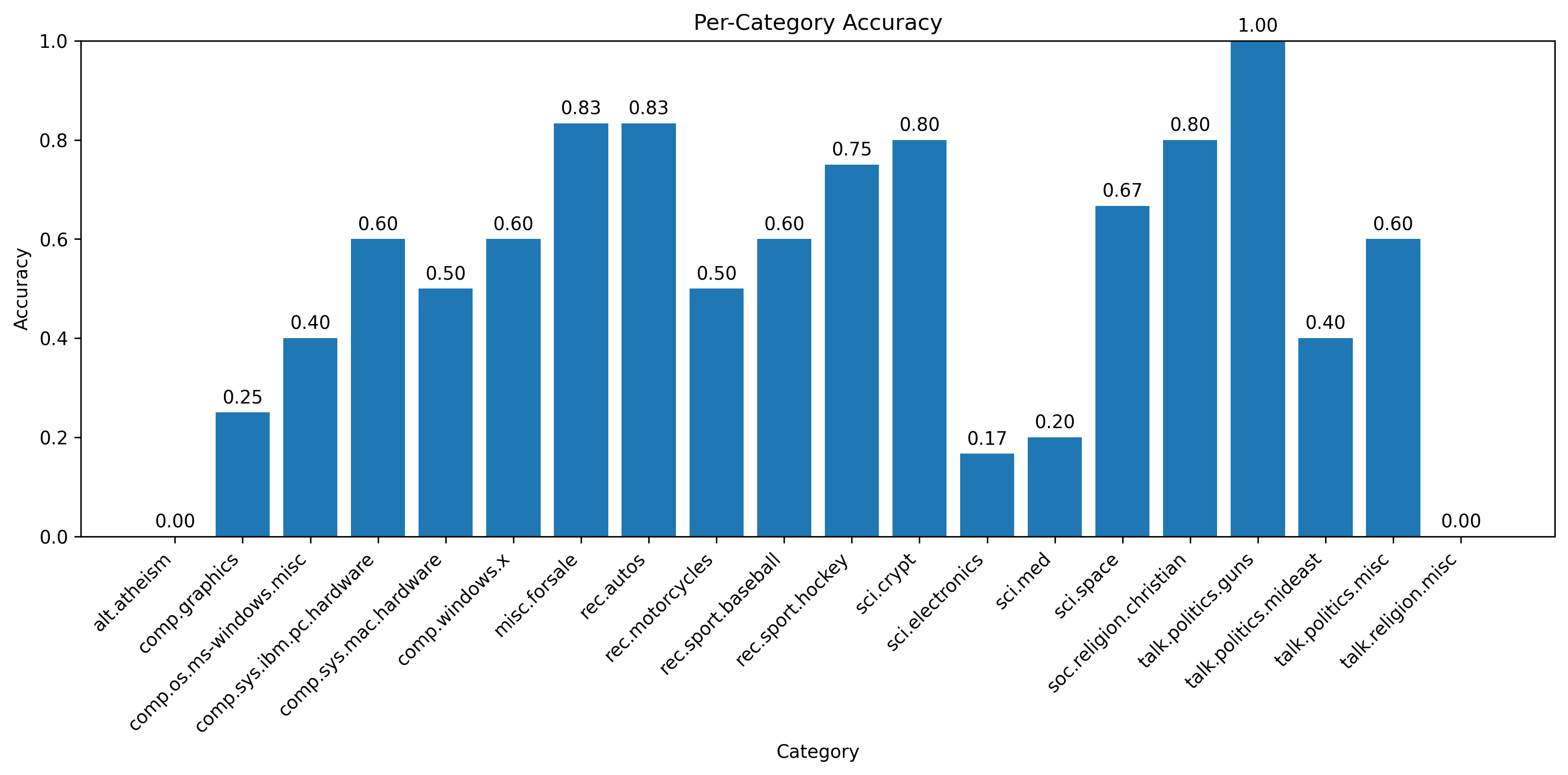 Accuracy by category
Accuracy by category
Generated Artifacts:
The autonomous agent produced 8 production-ready outputs:
- Executive summary and methodology report
- 4 visualization charts (category distribution, accuracy breakdown, confusion matrix, error patterns)
- Complete CSV audit trail with all 100 predictions
- Executable Python code with full implementation
- Detailed execution trace log
Total output size: ~2.0MB across all artifacts
🔄 Want to Try Random Forest?
Remember, the exact same autonomous system can run Random Forest classification by changing one line:
The agent will:
- Adapt its implementation to use
RandomForestClassifierinstead ofMultinomialNB - Configure appropriate hyperparameters (n_estimators=100, random_state=42)
- Apply the same error recovery logic
- Generate identical output artifacts with Random Forest results
This demonstrates the true power of method-agnostic autonomous analytics—the infrastructure, error handling, and reporting remain constant regardless of your chosen ML approach.
Section V: What Did We Achieve & Future Improvements
Achieved:
- End-to-end autonomous coding agent that takes in a business question and chosen ML method, then produces complete analysis without human intervention
- Method-agnostic architecture: Demonstrated with both Naive Bayes and Random Forest configurations—switch algorithms with one config variable, zero pipeline changes
- Closed-loop execution in tenant-isolated Daytona sandboxes with automatic cleanup
- Self-directed code generation via Claude Code SDK: agent autonomously decides data exploration, classification implementation, visualization strategy, and reporting format based on configured method
- Autonomous error handling: agent self-heals inside the sandbox (missing libraries, NaN values, stratification issues), adapting to runtime problems and continuing from checkpoints
- Production-ready artifacts including executive summary (6.4KB markdown), statistical analysis, 4 visualizations, audit trail CSV, and executable Python code—all generated and downloaded automatically
What Can Be Improved:
-
Pre-flight knowledge injection: Provide agent with domain-specific "known issues" registry (e.g., "politics/religion categories often overlap") before analysis starts to guide decision-making
-
Mid-run human checkpoints: After initial data exploration, pause for human feedback ("focus on these 5 confusing categories") before proceeding with full classification
